# 子查询
子查询(SubQuery)是指出现在其他 SQL 语句内的 SELECT 子句。
SELECT * FROM t1 WHERE col1=(SELECT col2 FROM t2);
# 其中,SELECT * FROM t1 称为 Outer Query/Outer Statement
# SELECT col2 FROM t2 称为 SubQuery
2
3
4
- 子查询指嵌套在查询内部,且必须始终出现在圆括号内
- 子查询可以包含多个关键字或条件,如 DISTINCT、GROUP BY、ORDER BY、LIMIT、函数等
- 子查询的外层查询可以是:SELECT, INSERT, UPDATE, SET, DO
- 子查询可以返回标量、一行、一列、子查询
子查询可以依据执行的次数划分为非关联子查询和关联子查询。(非关联子查询与主查询的执行无关,只需要执行一次即可;而关联子查询,则需要将主查询的字段值传入子查询中进行关联查询。)
- 非关联子查询:子查询从数据表中查询了数据结果,如果这个数据结果只执行一次,然后这个数据结果作为主查询的条件进行执行,那么这样的子查询叫做非关联子查询。
- 关联子查询:同样,如果子查询需要执行多次,即采用循环的方式,先从外部查询开始,每次都传入子查询进行查询,然后再将结果反馈给外部,这种嵌套的执行方式就称为关联子查询。
# EXISTS 子查询
关联子查询通常也会和 EXISTS 一起来使用,EXISTS 子查询用来判断条件是否满足,满足的话为 True,不满足为 False。同样,NOT EXISTS 是不存在的意思。
-- 查询出场过的球员都有哪些,并且显示他们的姓名、球员 ID 和球队 ID
SELECT player_id,team_id,player_name
FROM player
WHERE EXISTS (SELECT player_id FROM player_score WHERE player.player_id=player_score.player_id);
2
3
4
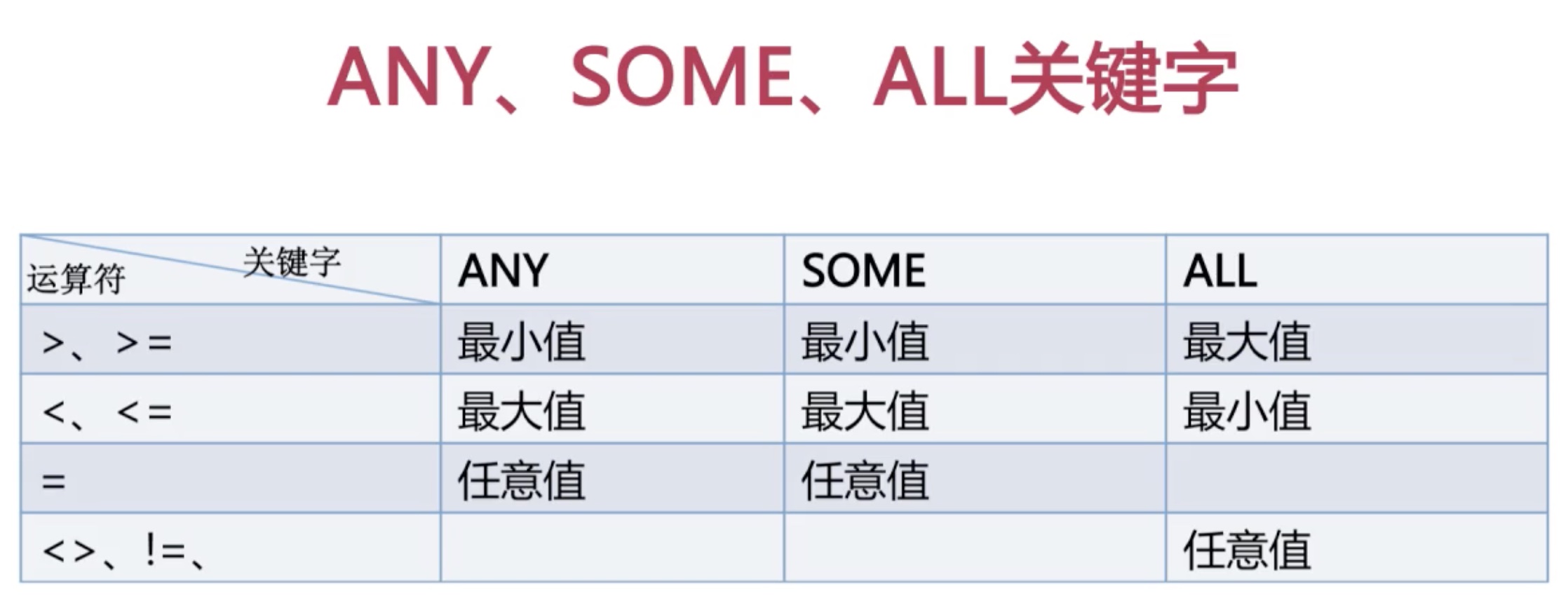
# 使用比较运算符的子查询
比较运算符:=、>、>=、<、<=、!=、<>、<=>
语法结构:operand comparison_operator [ANY | SOME | ALL] (subquery)
用 ANY, SOME, ALL 修饰(ANY 与 SOME 相同)
# 集合比较子查询
集合比较子查询的作用是与另一个查询结果集进行比较,我们可以在子查询中使用 IN、ANY、ALL 和 SOME 操作符
语法结构:operand comparison_operator [[NOT] IN] (subquery)
| 操作符 | 描述 |
|---|---|
| IN | 判断是否在集合中 |
| ANY | 需要与比较操作符一起使用,与子查询返回的任何值做比较 |
| ALL | 需要与比较操作符一起使用,与子查询返回的所有值做比较 |
| SOME | 实际上是 ANY 的别名,作用相同,一般常用 ANY |
=ANY 或 =SOME 与 IN 等效;!=ALL 或 <>ALL 与 NOT IN 等效
-- 查询出场过的球员都有哪些,并且显示他们的姓名、球员 ID 和球队 ID
SELECT player_id,team_id,player_name
FROM player
WHERE player_id IN (SELECT player_id FROM player_score);
-- 查询球员表中,比印第安纳步行者(对应的 team_id 为 1002)中任意一个球员身高高的球员信息,并且输出他们的球员 ID、球员姓名和球员身高
SELECT player_id,player_name,height FROM player WHERE height > ANY (SELECT height FROM player WHERE team_id=1002);
SELECT player_id,player_name,height FROM player WHERE height > (SELECT MIN(height) FROM player WHERE team_id=1002);
-- 查询球员表中,比印第安纳步行者(对应的 team_id 为 1002)中所有球员身高都高的球员的信息,并且输出球员 ID、球员姓名和球员身高
SELECT player_id,player_name,height FROM player WHERE height > ALL (SELECT height FROM player WHERE team_id=1002);
SELECT player_id,player_name,height FROM player WHERE height > (SELECT MAX(height) FROM player WHERE team_id=1002);
2
3
4
5
6
7
8
9
10
11
12
# 子查询作为主查询的计算字段(列)
-- 查询每个球队的球员数
SELECT team_id,team_name,(SELECT COUNT(*) FROM player WHERE player.team_id=team.team_id) AS player_num FROM team;
2
TIP
# EXISTS 和 IN 子查询效率的比较
SELECT * FROM A WHERE cc IN (SELECT cc FROM B);
SELECT * FROM A WHERE EXISTS (SELECT cc FROM B WHERE B.cc=A.cc);
2
A 表,又叫主表、外表;B 表,又叫从表、内表
实际上在查询过程中,在我们对 cc 列建立索引的情况下,我们还需要判断表 A 和表 B 的大小。如果表 A 比表 B 大,那么 IN 子查询的效率要比 EXISTS 子查询效率高,因为这时 B 表中如果对 cc 列进行了索引,那么 IN 子查询的效率就会比较高。
同样,如果表 A 比表 B 小,那么使用 EXISTS 子查询效率会更高,因为我们可以使用到 A 表中对 cc 列的索引,而不用从 B 中进行 cc 列的查询。
- 当查询字段进行了索引时,主表 A 大于从表 B,使用
IN子查询效率更高 - 相反主表 A 小于从表 B 时,使用
EXISTS子查询效率更高
# 小表驱动大表
哪个表小就用哪个表来驱动,A 表小就用 EXISTS (主小从大),B 表小就用 IN (主大从小,大表 IN 小表)。
当 A 小于 B 时,用 EXISTS。因为 EXISTS 的实现,相当于外表循环,实现的逻辑类似于:
for i in A
for j in B
if j.cc == i.cc then ...
2
3
当 B 小于 A 时,用 IN,因为实现的逻辑类似于:
for i in B
for j in A
if j.cc == i.cc then ...
2
3
# IN 与 EXISTS
假设 主表 A 有 n 条数据,从表 B 有 m 条数据,表 A 和表 B 中的查询字段采用 B+ 树进行索引,那么两个子查询的执行效率:
- 使用
IN: m * log(n) - 使用
EXISTS: n * log(m)
IN 子查询,是从表计算出来作为已知值,而 EXISTS 子查询是主表作为已知值传递给从表。
对于 IN 子查询,计算出来的结果作为已知值,就可以使得表 A(n 条数据)可以使用到索引,从而提升检索效率;
对于 EXISTS 子查询,外表 A 作为已知值,传递给从表,可以利用从表 B(m 条数据)中的索引,从而提升检索效率。
(说明 log 代表以2为底的对数,即 B+ 树的深度)
# NOT IN 与 NOT EXISTS
NOT IN是先执行子查询,得到一个结果集,将结果集代入外层谓词条件执行主查询,子查询只需要执行一次;NOT EXISTS是先从主查询中取得一条数据,再代入到子查询中,执行一次子查询,判断子查询是否能返回结果,主查询有多少条数据,子查询就要执行多少次。
IN 有一个缺陷是不能判断 NULL,如果字段存在 NULL 值,则会进行忽略,所以最好使用 NOT EXISTS